wsql
- 浏览: 11780410 次
- 性别:

- 来自: 深圳
-

最新评论
-
笨蛋咯:
获取不到信息?
C#枚举硬件设备 -
guokaiwhu:
能把plan的数据结构图画出来,博主的耐心和细致令人佩服。
PostgreSQL服务过程中的那些事二:Pg服务进程处理简单查询五:规划成plantree -
gao807877817:
学习
BitmapFactory.Options详解 -
GB654:
楼主,我想问一下,如何在创建PPT时插入备注信息,虽然可以解析 ...
java转换ppt,ppt转成图片,获取备注,获取文本 -
jpsb:
多谢 ,不过我照搬你的sql查不到,去掉utl_raw.cas ...
关于oracle中clob字段查询的问题
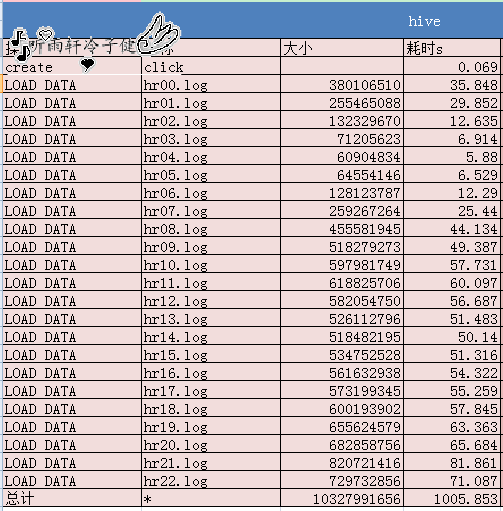
11G数据的hive初测试



相关推荐
HIVE实战测试数据HIVE实战测试数据HIVE实战测试数据HIVE实战测试数据
hive造数据
hive 操作相关的测试数据集hive
这个是hive测试数据.
TPCDS Hive基准测试流程完整总结;
大数据Hive测试数据uaction.rar,包含了用户操作记录,为文件大小为300余M,包含800W条数据。
hive测试题(包含万级测试数据文件)
《Hive数据仓库案例教程》教学课件 第5章 Hive数据操作.pdf《Hive数据仓库案例教程》教学课件 第5章 Hive数据操作.pdf《Hive数据仓库案例教程》教学课件 第5章 Hive数据操作.pdf《Hive数据仓库案例教程》教学课件 第...
文章Hive面试题SQL测试题目所需数据,包含建表语句 测试数据等等...................
Hive.sql
文章Hive面试题SQL测试题目所需数据,包含建表语句 测试数据等等...................
datax数据从hive表导入mysql表,数据缺失解决
(3)sqoop数据迁移,完成HIve与MySQL数据库中的数据交互 (4)Echarts搭建动态可视化大屏 (5)SpringBoot搭建可视化后台系统,完成前端与后台的数据传递与交互。 (6)基于Cenots7 搭建虚拟机,配置Hadoop、HDFS、...
一种基于数据仓库工具Hive组件的测试方法及系统.pdf
1.将Mysql中的数据迁移到Hdfs文件系统中,然后通过Hive加载HDFS文件系统中的数据值 2.将Hive中的数据迁移到指定Mysql数据库中 注意点: 1.数据迁移的过程中,由于hive的Null值存储为"\N",Mysql存储为NULL值,二者...
林子雨Hive数据集下载
数据分析系统Hive
Ambari搭建hadoop环境下,hive的数据导入
《Hive数据仓库案例教程》教学大纲.pdf《Hive数据仓库案例教程》教学大纲.pdf《Hive数据仓库案例教程》教学大纲.pdf《Hive数据仓库案例教程》教学大纲.pdf《Hive数据仓库案例教程》教学大纲.pdf《Hive数据仓库案例...
因为你不知道将Hive的数据导入到了ElasticSearch后,数据量是否准确,所以需要钉钉报警校验ElasticSearch和Hive数据仓库内的数据质量,注意,这个项目打包后,最好另起一个进程调用,并且开始时间为文章1或者2最大...