Select语句的大致格式:
Select[All | Distinct ] [Topn[Percent] ] select_list
[Intonew_table] From {table_name|view_name[,table_name2|view_name2] [, ……]} [Where search_condition]
[Group bygroup_by_list] [Havingsearch_conditon] [Order by order_list [Asc|Desc]]
Select语句的大致分类及执行顺序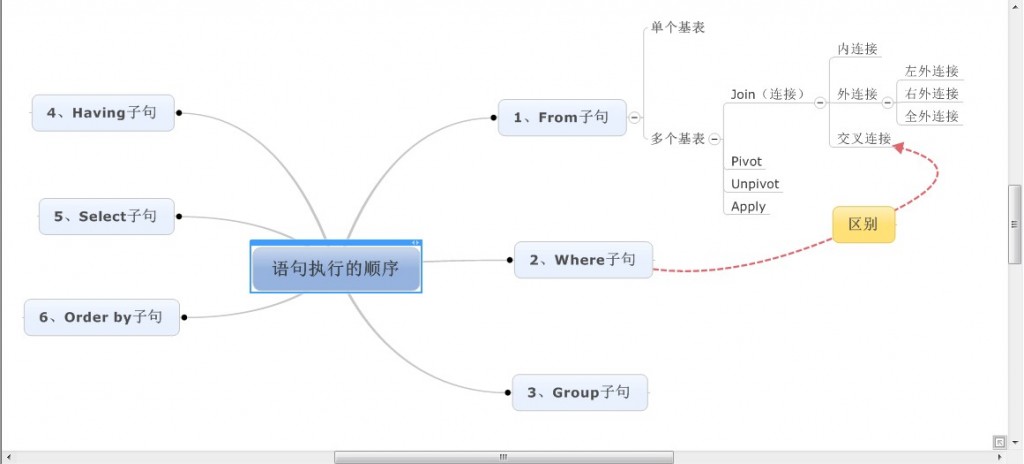
1、From子句
1-1、From子句的概述
From子句的主要任务是表示出查询的来源表,并处理表的运算。在T-SQL的Select语句中首先要执行的是From子句,这一点也体现出该语句的一个特点:子句的执行顺序并不是按照编写顺序来的。对于先执行From子句是很好理解的,按照事物的发展顺序我们可以知道,我们必须先确定源表,然后才能进行以后的操作。
1-2、From子句具有的功能
1-2-1、单表:
1-2-1-1、确定表的来源;
1-2-1-2、我们也可以加上一些对表的运算,如行变列操作或列变行操作等。
1-2-2、多表:
1-2-2-1、确定多表来源;
1-2-2-1、建立表和表之间的关系(联接)。
!-1、为什么要加表与表之间的关系呢?
确定多个表的信息后,计算机会先把多个表中的各各记录按笛卡尔积的形式组成一个新的表(B1-1),也就是说,一个表中的一条记录要和另一个表中的所有记录,分别组成一个新的记录,为了得到唯一性,我们要建立表和表之间的关系,当然,我们也可以在Where子句中创建,这两者之间有区别,后续介绍;
!-2、表和表的联接方式及解释
@-1、三种联接方式
内连接、外连接、交叉连接
@-2、外连接的分类
外连接分为左外连接、右外连接、全外连接;外连接只是这三种实在操作的一个总称。
@-3、外连接的解释
以左外联接为例:表示形式为 A数据表 left [outer] join B数据表 on 结合的条件,以A中的记录为基准根据结合条件找数据组成新的记录,如果B中没有满足结合条件的记录,那么新纪录中只有A中记录,没有B中记录。这是左外联接,自己可以推出右外连接和全外连接。
1-3、From子句内部执行的大致过程
根据From中的表源,计算机把各各表中的记录做笛卡尔积运算,组成一个新记录所组成的虚拟表B-1-1;根据on后的结合条件,计算机从B-1-1中筛选出新记录,组成一个新的虚拟表B-1-2;根据表和表之间的联接关系,增加记录时,计算机生成一个新的虚拟表B-1-3。大家可以想一想为什么要这样的顺序,限于篇幅,在此不讲了。
2、Where子句
2-1、Where子句的执行过程
where根据<where_predicate>条件,对虚拟表B-1进行筛选,把所有符合条件的记录组成一个新的虚拟表B-2.
2-2、Where 条件和on(join中) 条件区别
从1-3和2-1中的叙述可知,如果From子句只生成虚拟表B-1-2,那么,where可以达到on的效果,如果From子句生成B-1-3表(不同于B-1-2),那么,on和where的效果就不同了。换句好说:对于内连接,where和on的作用完全一样;对于外连接,on和where存在区别,on筛选后的结果并不是最终的结果,还要进行新的筛选:把外部行添加上去,而where是对添加了外部行的表的筛选。
2-3、Where子句中的注意
不能引用select子句中表的别名,因为还没有执行到那里;不能用聚合函数,因为此时的记录还没有分组,也就是说Group by语句还没有执行到。
3、Group by子句
3-3、Group by子句的目的
Group by子句的目的,也可以说成分组的目的,分组就是为了进行聚合计算,也就是应用聚合函数(Avg、Sum、Min、Max、Count)。
3-2、Group by子句的执行过程
计算机按要求把虚拟表B-2中的记录(个数不等)组合成一个组,并且把这些组当成新的记录生成一个新的虚拟表B-3。
3-3、Group by中的with cube和rollup的区别
首先要明白:分组也可以分等级的分组;
with cube 使聚合函数应用在每一等级上的组,也就是说,聚合函数的应用,返回每一级上的组聚合运算后生成的记录;
with rollup 只使聚合函数的范围在第一级上的组,也就是说,聚合函数的应用,只返回第一层分组聚合运算后生成的记录。
4、Having子句
4-1、Having子句和Where子句的区别
Having子句和Where子句的区别,操作的对象不同。Having子句的对象是虚拟表中B-3中的记录,也就是说,Having子句的对象是组,而Where子句的对象是B-1中的记录。根据上述,我们也知道,Having子句主要是和Group
by子句一起使用。
4-2、Having子句的执行过程
当计算机完成Group by子句生成虚拟表B-3,此时,计算机再根据Having子句中的条件进行对B-3进行筛选,筛选出来的记录再组成一个新的虚拟表B-4。
5、Select子句
5-1、Select子句的执行过程
根据Select中的字段名或字段名的运算,从虚拟表B-4中等到相应的结果,组成记录,然后这些记录组成一个新的虚拟表B-5-1;(注意:当所选结果为字段名的运算时,我们自己可以为该列起一个字段名,也可以让系统起一个新的字段名;Select列表中,所有的表达式是同时计算的,最简单的例子,两个变量的值进行交换,我们不用定义第三个变量就可以交换。)
执行关键字All和Distinct。如果关键字是Distinct,那么就需要把虚拟表B-5-1中相同的记录删去,得到的新的记录再组成一个新的虚拟表B-5-2,关键为All时不用变,默认没有此类关键字时为关键字All;
执行关键字Top n [Percent]。当为Top n [Percent]时,计算机把从虚拟表中B-5-2选择n条或百分之n的记录组成新的虚拟表B-5-3。
6、Order by子句
6-1、Order by的执行过程
根据指定的字段名进行排序,此时的字段名内的一条记录跟着该列的变动而变动,最终从虚拟表B-5生成游标B-6。(游标的概念在后期补充)
6-2、Order by和Group by的区别
Group by是分组,把一个表中多条相应的记录归为一组,而这一组记录在新的虚拟表中的体现却仅仅是一条记录;
Order by是排序,把一个表中的记录,按一定的要求从新排一下序列,排好了序列的表就是新的表。(关键字Asc为升序,关键字Desc为降序,默认为升序)
注意:上述中的表的概念还指视图等表;Select语句中不是必须的经历没有一个过程,所以我们要注意每个过程所用到的虚拟表,虽然,在写的时候,我们写的名称对应紧挨着它的上一个过程的表,但是,我们要知道,这个含义,没给个过程用到的表名在具体的时候是灵活变动的。例如:我们没有写Having子句,那么,我们Select子句中的B-4指的就是别的表了。大家要理解这层含义
体会:这篇博客耗时2天多;写完这篇博客后,一个字:爽!
分享到:





相关推荐
11. 基础-SQL-DQL-基础查询 12. 基础-SQL-DQL-条件查询 13. 基础-SQL-DQL-聚合函数 14. 基础-SQL-DQL-分组查询 15. 基础-SQL-DQL-排序查询 16. 基础-SQL-DQL-分页查询 17. 基础-SQL-DQL-执行顺序 18. 基础-SQL-DCL-...
无 个人操作记录
4. DQL-条件查询 - 副本.sql
SQL语言,SQL Server数据库,T-SQL特性,DQL数据查询语句,SQL语法、高级查询、模糊查询和聚合查询、连接查询和分组查询相关知识点学习总结
4. DQL-条件查询.sql
SQL中DQL语言笔记
DQL(数据查询语言)、DML(数据操纵语言) 二、SQL的特点 SQL 语句不区分大小写 SQL 语句能输入一行或多行 关键字不能整行缩写或分离 子句通常被放置在分开的行上 缩进可提高可读性 在SQL 开发工具,SQL ...
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。1. 数据查询语言DQL数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:SELECT <字段名表>FROM...
数据库SQL语句总结 DQL数据查询语言
MySQL基本查询-DQL
强化学习(八)-深度Q学习(DeepQ-learning-DQL-DQN)原理及相关实例 深度学习原理.pdf
DQL:data Query language 数据查询语言 格式:select[distinct] 字段1,字段2 from 表名 where 控制条件 (distinct: 显示结果时,是否去除重复列 给哪一列去重就在哪一列字段前加入distinct) 学生表 (1)查询表中...
DDL+DML+DQL+
DDL+DML+DQL+
DDL+DML+DQL+
BD-1.dql
SQL Server使用ANSI SQL-92的扩展集,称为T-SQL,其遵循ANSI制定的 SQL-92标准。 SQL语言包含4个部分: 数据定义语言(DDL),例如:CREATE、DROP、ALTER等语句。 数据操作语言(DML),例如:INSERT(插入)、...
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML, 数据定义语言DDL,数据控制语言DCL。